연관토픽
기출문제
| 회차 | 문제 |
| 응용111-2 | 3. 하둡 분산파일시스템(HDFS: Hadoop Distributed File System)의 특징 및 구조에 대하여 설명하고, 구성요소인 네임노드, 데이터 노드의 역할에 대하여 설명하시오. |
개념
- 저비용의 수백 내지 수천 노드를 가지는 클러스터를 이용하여 페타 바이트의 대용량 데이터 집합을 처리하는 응용 프로그램에 적합하도록 설계한 분산 파일 시스템
- x86서버에 장착된 저가의 SATA 디스크를 이용하여 데이터를 분산 시스템에 중복 저장, 가용성을 향상시킨 분산 파일 시스템

HDFS의 특징
| 구분 | 특징 | 설명 |
| 분산저장 | Scale-Out | 자원의 추가에 따른 가용량 및 성능의 선형적 증가 |
| 블록저장 | 1 files = n block, 1 block = 64/128MB, 1 block = 3 replica | |
| 다중복제 | 하나의 블록을 여러 노드에 복제하여 HA 구현 |
|
| 대량파일 저장 | 파일 정보를 NameNode 에서 관리, 대규모 파일 저장 |
|
| 시스템 운영 | 범용장비 사용 | 저가의 x86 서버, SATA 디스크 기반의 클러스터 구성 |
| 고가용성(HA) | 특정 노드 장애 발생 시에도 중단 없이 서비스 가능 | |
| 접근성 | JavaAPI,C 래핑 등 응용프로그램에서 접근성 제공 |
HDFS 아키텍처

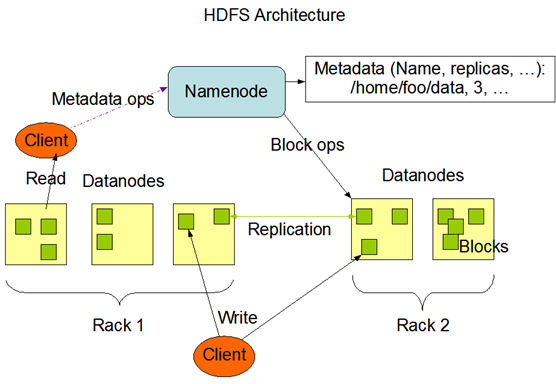
- 네임노드는 파일시스템의 네임스페이스(디렉토리, 파일명, 파일블럭)등을 관리하며 클라이언트의 요청 처리
- 블록들은 가용성을 보장하기 위해 여러 데이터 노드에 분산 저장
HDFS 구성요소
| 특징 | 내용 |
| Name node | 마스터노드, 데이터노드의 메타정보를 관리함, 블록의 정보 저장 |
| Data node | 슬레이브노드, 복제 데이터 저장 |
| Secondary Name Node | Name Node의 Metadata 로드가 실패시 Backup Node로써 사용 |
| Job Tracker | 분산 환경에서 작업을 분산시키는 스케줄 작업(master : Task Tracker에 작업 할당) |
| Task Tracker | Data Node에서 Map-Reduce 역할을 수행(slave : 할당 받은 작업을 처리함) |
HDFS 동작원리

- 파일을 생성하기 위해 클라이언트 Namenode로 /foo/var 파일 패스에 대한 생성 요청
- Namenode는 메모리상에 해당 파일 패스정보를 생성하고 해당 패스의 대해 Lock을 걸음
- Namenode는 파일을 저장할 Data Node를 선택해 host 정보를 Client로 반환
- 파일을 저장할 Data node의 목록을 받은 클라이언트는 파일 데이터를 전송
- 파일 데이터를 받은 Data Node는 데이터를 로컬 디스크(Local disk)에 저장하고 다음 Data Node로 전송 (기본 3번 복제)
- 만약 Data 크기가 블록을 넘어서면 Client는 Name Node에게 새로운 Data Node를 요청
- Namenode는 메모리에 임시로 저장되어 있던 파일 패스의 정보를 영구 파일 패스 정보로 이동 시킴, Namenode 재시작 시에도 패스에 대한 정보가 존재 하도록 Namenode의 로컬 디스크에 파일 생성 관련 로그를 저장 (이 파일을 edits라고 함)
- Namenode는 클라이언트에게 요청에 대한 Data Node 정보를 전달
- 클라이언트는 4~5번 과정을 반복하고 경우에 따라 6번 7번 작업을 반복
- 파일 전송이 완료되고 close() 명령을 namenode로 전달
- Secondary Namenode는 주기적으로 edits파일을 namenode로부터 다운로드 해서 namespace 정보를 저장하고 있는 fsimage 파일과 병합해서 새로운 fsimage 파일을 생성해 namenode로 전송
- Namenode는 기존의 fsimage파일을 새로운 파일로 대체하고 edits 파일을 새로운 파일로 만듬
- Namenode 재 시작 시에는 fsimage 파일을 읽어 메모리를 구성한 후 edits 파일의 변경 내역을 하나씩 수행하는 방식으로 메모리를 재구성
HDFS의 장점
| 장점 | 내용 |
| 선형적인 확장성 제공 | HDFS를 이용하는 경우 서비스 초기에 필요한 수준의 스토리지만 구성하고, 추후 용량 추가가 필요한 시점에 용량을 추가 할 수 있음 |
| 글로벌 네임스페이스 제공 | 회사 전체의 시스템이나 전체 서비스에서 파일에 대한 유일한 식별 단위를 가질 수 있음 |
| 전체 처리 용량 증가 | 분산된 서버의 디스크를 이용하기 때문에 네트워크, Disk I/O 등이 각 서버로 분산 되어 처리 됩니다 |
| 데이터 분석 처리에 활용 | 분석용 데이터를 HDFS에 저장하고 맵리듀스를 이용해 분석 |
HDFS의 단점
| 단점 | 내용 |
| 응용 프로그램 기반 파일 시스템 | - 일반적인 파일 시스템처럼 ls, copy, rm 등과 같은 명령어를 사용하지 못함 |
| 불변 파일 (Immutable file)만 저장 |
- HDFS에서는 파일이 한번 써지면 변경되지 않는다고 가정 - 이미 저장된 파일을 오픈해 특정위치에 데이터를 수정 할 수 없음 |
| 네임스페이스 관리를 네임 노드 메모리에 저장 | - 파일 시스템의 네임스페이스 정보를 네임 노드의 메모리 상에서 관리 하기 때문에 하둡에 저장할 수 있는 파일 과 디렉토리의 개수는 네임 노드의 메모리 크기에 제한 - 네임 노드는 하나의 파일 정보를 저장하는데 수백 byte를 사용 |
| 네임 노드 이중화 문제 | - Data Node들은 장애가 발생해도 서비스에 지장이 없지만 네임 노드에 장애가 발생하면 파일 시스템 전체에 장애가 발생 |
Reference