연관토픽
기출문제
| 회차 | 문제 |
| 관리116-1 | 2. SQL(Structured Query Language) |
개념
- 사용자가 정의된 질의를 통하여 데이터베이스를 제어하고 관리할 수 있도록 해주는 표준 구조화 질의 언어
- 관계 데이터베이스 관리시스템에서 자료 검색과 관리, 스키마 생성 및 수정, 객체 접근 조정관리를 위한 프로그래밍 언어
- 관계 사상(relational mapping)을 기초로 한 입력 릴레이션(테이블)으로부터 원하는 출력 릴레이션을 사상(mapping)시키는 대표적인 언어
- 사용자가 데이터베이스를 구축하고 이에 접근하기 위해 데이터베이스 관리 시스템과 통신하는 수단
- 관계형 데이터베이스 관리 시스템(RDBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어
SQL의 특징
| 특징 | 설명 |
| 스키마 관리 | - 스키마 객체의 생성, 변경, 제거 |
| 관계형 언어 | - 입력 릴레이션으로부터 원하는 출력 릴레이션으로 사상시키는 관계형 언어 |
| 데이터 관리 | - 데이터베이스 질의, 데이터 삽입/갱신/삭제 |
| SQL 표준 | - SQL2(SQL92) : 관계형 데이터베이스 위한 언어 - SQL3(SQL99) : SQL2에 객체지향 개념 확장한 객체 관계형 데이터베이스 언어 |
SQL 종류

- 사용자와 데이터베이스 관리 시스템 간의 통신 수단
- 사용 목적에 따라 데이터 정의어, 데이터 조작어, 데이터 제어어로 구분
| 구분 | 설명 | SQL문 |
| 데이터 정의어(DDL) | - 테이블이나 관계의 구조를 생성하는데 사용 - 테이블을 생성하고 변경, 제거하는 기능 제공 |
CREATE, ALTER, DROP 등 |
| 데이터 조작어(DML) | - 테이블에 데이터를 검색, 삽입, 수정, 삭제 - 테이블에 새 데이터 삽입하거나, 테이블에 저장된 데이터 수정, 삭제, 검색 기능 |
SELECT, INSERT, DELETE, UPDATE 등 |
| 데이터 제어어(DCL) | - 데이터의 사용 권한을 관리하는데 사용 - 데이터에 대한 접근 및 사용권한을 사용자별로 부여하거나 취소하는 기능 |
GRANT, REVOKE 등 |
SQL 처리과정
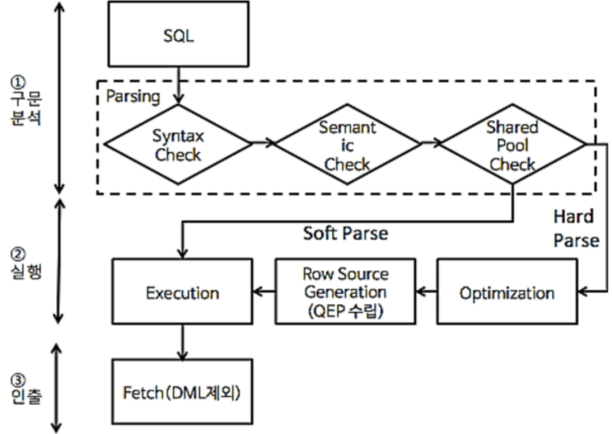
- SQL 처리는 구문분석, 실행, 인출(DML의 경우 생략) 과정으로 수행, 기 사용 SQL 문에 대해서는 Shared Pool의 기 사용 내역 검색을 통해 과정 간소화
| 구분 | 처리과정 | 설명 | 비고 |
| 구문분석 (parsing) |
Syntax Check | SQL 문장의 구문 분석 | Parpared Statement에서는 생략 |
| Semantic Check | SQL 문장의 의미 및 문법적 적절성 체크 | ||
| Shared Pool Check | 쿼리에 사용된 테이블, 컬럼, 뷰 등 존재 여부확인 | ||
| Optimization | 쿼리 수행을 위한 최적의 실행방법 선택(RBO/CBO) | ||
| Execution Plan | 쿼리 실행 계획 수립 | ||
| 실행 (Execution) |
캐쉬 데이터 검색 | 메모리 영역의 데이터베이스 캐쉬영역을 검색하여 해당 객체가 존재하는지 확인 | Cache Database file |
| 데이터 파일 검색 | 캐쉬 내에 존재하지 않는 경우, 데이터베이스 파일을 검색하여 해당 데이터를 캐쉬 영역에 저장 | ||
| 인출(fetch) | 데이터 인출 | 관련 테이블 데이터를 처리하여 사용자에게 전송 | DML 생략 |
SQL 수행요소
| 구분 | 역할 | |
| Parser | - SQL 문장을 이루는 개별 구성요소를 분석하고 파싱해서 파싱 트리 생성 - SQL 문법적 오류, 의미상 오류 확인 |
|
| Optimizer | Query Transformer | - 파싱된 SQL을 일반적이고 표준적인 형태로 변환 |
| Estimator | - 쿼리 수행 각 단계의 선택도, 카디널리티, 비용을 계산하고 실행계획 전체의 총 비용을 계산 | |
| Plan Generator | - 하나의 쿼리를 수행하는데 있어, 후보군이 될만한 실행게획들을 생성 | |
| Row-Source Generator | - 옵티마이저가 생성한 실행계획을 SQL 엔진이 실제 실행할 수 있는 코드 형태로 생성 | |
| SQL Engine | - SQL 실행 | |
SQL 수행 성능향상 절차

- 데이터 모델의 확인과 인덱스 유효성이 선행된 이후 테이블 조인의 최적 플랜을 검증하여 SQL 수행 성능을 향상함
SQL 수행 성능향상 기법
| 구분 | 설명 | 예시 |
| 옵티마이저 | 옵티마이저의 목표: SQL로 요구된 결과를 최소의 비용으로 처리할 수 있는 처리경로를 결정 - SQL은 처리절차를 기술한 것이 아니라 결과에 대한 요구일 뿐임. -새로운 길을 만드는 것이 아니라 이미 존재하는 길을 단지 찾아줄 뿐임 -사용자가 부여한 영향요소(예:힌트)에 따라 논리적으로 존재하는 최적은 달라짐. -동일한 결과를 얻을 수 있는 경로는 많으나 효율성의 차이는 큼. -옵티마이져는 절대 전지전능하지 않음. |
|
| 힌트(hint) 사용 | - 옵티마이저가 항상 최적화된 실행계획을 수립하는 것은 아니므로 힌트를 사용하여 원하는 실행계획으로 유도 | SELECT /*+ hint [ { hint } ... ] */ |
| 부분범위 처리 | - 조건을 만족하는 전체집합이 아닌 일부분만 액세스하고도 결과를 리턴 할 수 있도록 하여 온라인 프로그램에서 응답시간(Response Time)을 최소화 할 수 있음 | - 인덱스를 이용해서 sort 대체 - 인덱스만으로 액세스해도 되는 구조를 만듦 - max값을 구할 경우 인덱스 이용 - exists 활용 - rownum 활용 |
| 인덱스 활용 | - 인덱스가 있음에도 불구하고 SQL을 잘못 기술함으로써 무용지물로 만드는 오류를 없애야 함 | 인덱스 활용을 위해 아래 경우 배제 - 인덱스 칼럼의 변형 - not operator - null, not null 사용 |
| 조인방식/조인순서 | - 동일한 SQL문이라도 조인방식과 조인순서에 따라 처리속도는 매우 큰 차이를 가져올 수 있으므로 작성한 SQL이 어떤 실행계획으로 수립되는 지 반드시 확인 후 조정 | |
| 다중처리 (array processing) |
- 배치작업의 경우 한번의 DBMS호출로 여러 건을 동시에 처리할 수 있는 다중처리 활용 | |
| 병렬쿼리 (parallel query) |
- 배치작업의 경우 하나의 SQL을 여러 개의 CPU가 병렬로 분할 처리하게 함으로써 처리속도 향상 가져옴 | Insert /*+ parallel(member_tmp,8)*/ into member_tmp Select /*+ parallel(member,8)*/ from member; |
| Dynamic SQL 지양 | - 조건절에 입력된 값을 먼저 Binding 한 후 실행계획을 수립하는 Dynamic SQL은 파싱 부하가 커지므로 입력 값을 Binding 하기 전에 실행계획을 수립하는 Static SQL을 가급적 사용하도록 함 | Select * From Tab Where Col1 = ‘1’; Select * From Tab Where Col1 = ‘2’; Select * From Tab Where Col1 = ‘3’; → Select * From Tab Where Col1 = :v1; |
Statement와 Prepared Statement 방식 비교
| 구분 | Statement | Prepared Statement |
| 개념 | 쿼리 실행시, 쿼리분석 -> 컴파일 -> 실행 과정 매번 진행 | 쿼리 실행시, 쿼리분석 -> 컴파일 -> 실행 과정을 최초 한번만 수행 후 캐쉬 저장 재사용 |
| 처리형태 | 일반 SQL 처리 | Bind SQL |
| 저장 | 없음 | Library Cache 저장 |
| 파싱형태 | Soft Parsing | Soft Parsing |
| 재사용 | 없음 | Cache 저장, 재사용 |
| 특징 | 실행시 마다 쿼리 실행과정 수행 | 쿼리 실행과정 최소 1회 수행 |
| 장점 | SQL 문장 파악 용이 | 동일 쿼리 반복 시 최적화 |
| 단점 | SQL 수행시 매번 컴파일 진행 | Where절이 가변적, SQL 확인 어려움 |
| 특이사항 | 성능 이슈 발생 가능 | 보안 강화, 안정적 |
| 실행절차 |  |
 |
모범답안
- [답안] SQL 처리과정, Statement와 Prepared Statement 비교 (2교시)
- [답안] SQL처리과정, Statement방식과 Prepared statement 비교 (2교시)